
Dalam machine learning, jumlah dan kualitas data diperlukan untuk model training dan performa model. Jumlah data sangat memengaruhi pembelajaran mesin dan algoritma deep learning. Sebagian besar perilaku algoritma berubah jika jumlah data bertambah atau berkurang.
Tetapi dalam kasus data terbatas, algoritma machine learning perlu ditangani secara efektif untuk mendapatkan hasil yang lebih baik dan model yang akurat. Algoritma deep learning juga membutuhkan data dalam jumlah besar untuk akurasi yang lebih baik.
Pada artikel ini, kita akan membahas hubungan antara jumlah dan kualitas data dengan pembelajaran mesin dan algoritma deep learning, masalah keterbatasan data, dan keakuratan penanganannya. Pengetahuan tentang konsep kunci ini akan membantu seseorang memahami algoritma dan skenario data sehingga kalian dapat menangani data terbatas secara efisien.
Grafik Jumlah Data vs Performa
Dalam machine learning, sebuah pertanyaan dapat muncul di benak kita, seberapa banyak data yang diperlukan untuk melatih pembelajaran mesin yang baik? Yah, tidak ada jawaban pasti untuk ini, karena setiap informasi berbeda dan memiliki fitur dan pola yang berbeda. Namun, ada beberapa level ambang batas yang setelahnya performa pembelajaran mesin atau algoritma deep learning cenderung konstan.
Sebagian besar waktu, model pembelajaran mesin dan pembelajaran mendalam cenderung berkinerja baik ketika jumlah data yang dimasukkan meningkat. Tetapi setelah beberapa titik atau sejumlah data, perilaku model menjadi konstan dan berhenti belajar dari data.
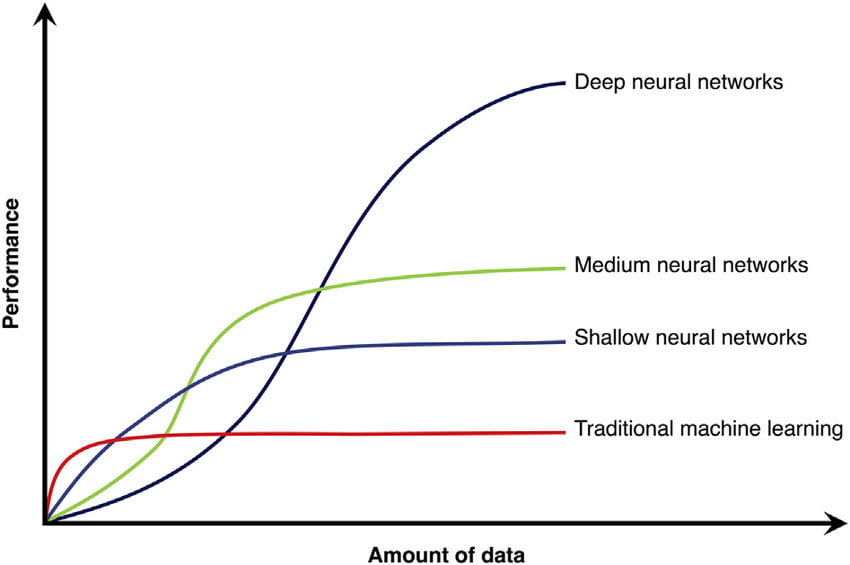
Gambar di atas menunjukkan kinerja beberapa pembelajaran mesin terkenal dan arsitektur pembelajaran mendalam dengan jumlah data yang dimasukkan ke algoritma. Di sini kita dapat melihat bahwa algoritma pembelajaran mesin tradisional belajar banyak dari data pada periode awal, di mana jumlah data yang dimasukkan meningkat, tetapi setelah beberapa waktu, ketika level ambang batas datang, kinerjanya menjadi konstan. Sekarang, jika kita memberikan lebih banyak data ke algoritma, algoritma tidak akan mempelajari apa pun dan versinya tidak akan bertambah atau berkurang.
Dalam kasus algoritma deep learning, ada total tiga jenis arsitektur deep learning dalam diagram. Jenis dangkal dari struktur pembelajaran mendalam adalah arsitektur pembelajaran mendalam kecil dalam hal kedalaman, yang berarti bahwa ada beberapa lapisan dan neuron tersembunyi dalam arsitektur pembelajaran mendalam eksternal.
Dalam kasus deep neural network, jumlah lapisan dan neuron tersembunyi sangat tinggi dan dirancang dengan sangat mendalam. Dari diagram, kita dapat melihat total tiga arsitektur deep learning, dan ketiganya bekerja secara berbeda ketika sejumlah data dimasukkan dan ditingkatkan.
Masalah Apa yang Muncul dengan Data Terbatas?
Beberapa masalah terjadi dengan data yang terbatas, dan model dapat bekerja lebih baik jika dilatih dengan data yang terbatas. Masalah umum yang muncul dengan data terbatas tercantum di bawah ini:
1. Klasifikasi:
Dalam klasifikasi, jika jumlah data yang dimasukkan rendah, maka model akan salah mengklasifikasikan pengamatan, artinya tidak akan memberikan output class yang akurat.
2. Regresi:
Dalam masalah regresi, jika akurasi modelnya rendah, maka model tersebut akan memprediksi dengan sangat salah, artinya karena ini adalah masalah regresi, maka akan diharapkan angkanya. Namun, data yang terbatas mungkin menunjukkan jumlah yang mengerikan jauh dari hasil sebenarnya.
3. Clustering:
Model dapat mengklasifikasikan titik-titik yang berbeda di cluster yang salah dalam masalah clustering jika dilatih dengan data yang terbatas.
4. Time Series:
Dalam analisis time series, kami memperkirakan beberapa data untuk masa mendatang. Namun, model time series dengan akurasi rendah dapat memberi kita hasil prakiraan yang lebih rendah, dan mungkin ada banyak kesalahan terkait waktu.
5. Object Detection:
Jika model deteksi objek dilatih pada data terbatas, mungkin tidak mendeteksi objek dengan benar, atau dapat mengklasifikasikan objek secara tidak benar.
Bagaimana Mengatasi Masalah Keterbatasan Data?
Perlu ada metode yang akurat atau tetap untuk menangani data yang terbatas. Setiap masalah pembelajaran mesin berbeda, dan cara memecahkan masalah tertentu berbeda. Tetapi beberapa teknik standar sangat membantu untuk banyak kasus.
1. Augmentasi Data
Augmentasi data adalah teknik di mana data yang ada digunakan untuk menghasilkan data baru. Di sini informasi lebih lanjut yang dihasilkan akan terlihat seperti data lama, tetapi beberapa nilai dan parameter akan berbeda di sini. Pendekatan ini dapat meningkatkan jumlah data, dan ada kemungkinan besar untuk meningkatkan performa model. Augmentasi data lebih disukai di sebagian besar masalah deep learning, di mana data dengan gambar terbatas.
2. Imputasi
Di beberapa kumpulan data, ada sebagian besar data yang tidak valid atau kosong. Oleh karena itu, sejumlah data dihilangkan bukan untuk memperumit proses, tetapi dengan melakukan ini, jumlah data berkurang, dan beberapa masalah dapat terjadi. Untuk menghadapinya, kita dapat menerapkan teknik imputasi data ke atribut data. Meskipun mengosongkan data bukanlah metode yang sederhana dan akurat, beberapa atribut canggih seperti KNNImputer dan IterativeImputer dapat digunakan untuk imputasi data yang akurat dan efisien.
3. Pendekatan Khusus
Jika ada kasus data yang terbatas, seseorang dapat mencari data di internet dan menemukan data yang serupa. Setelah jenis data ini diperoleh, dapat digunakan untuk menghasilkan lebih banyak data atau digabungkan dengan data yang ada. Pengetahuan domain dapat membantu menyalakan dalam kasus ini. Pakar domain dapat memberi saran dan memandu mengatasi masalah ini dengan sangat efisien dan akurat.