
Pada artikel kali ini, kita akan belajar dasar-dasar naive bayes dalam machine learning, sehingga lain kali ketika kita menemukan kumpulan data yang banyak, kita dapat menggunakan algoritma klasifikasi naive bayes dalam pembelajaran mesin untuk mengklasifikasi data tersebut.
Selain itu, jika kalian seorang pemula di Python, kalian tidak perlu khawatir dengan adanya code yang nantinya digunakan pada artikel ini karena akan saya jelaskan secara detail setiap baris codenya.
Apa itu Algoritma Naive Bayes?
Naive Bayes adalah algoritma klasifikasi berdasarkan teorema bayes dengan asumsi independesi antar prediktor. Secara sederhana, pengklasifikasi naive bayes mengasumsikan bahwa keberadaan fitur tertentu di kelas tidak terkait dengan keberadaan fitur lainnya.
Misalnya, buah dapat dianggap sebagai apel jika berwarna merah, bulatm dan berdiameter sekitar 3 inci. Bahkan jika ciri-ciri ini bergantung satu sama lain atau pada keberadaan ciri-ciri lain, semua sifat ini secara mandiri berkontribusi pada kemungkinan bahwa buah ini adalah apel dan itulah sebabnya algoritma ini dikenal sebagai Naive.
Model naive bayes mudah dibuat dan sangat berguna untuk kumpulan data yang sangat besar. Teorema bayes memberikan cara menghitung probabilitas posterior P(c|x) dari P(c), P(x) dan P(x|c). Perhatikan persamaan di bawah ini:

Keterangan:
- P(c|x) adalah probabilitas posterior kelas (c, target) yang diberikan prediktor (x, atribut).
- P(c) adalah probabilitas kelas sebelumnya.
- P(x|c) adalah kemungkinan yang merupakan probabilitas prediktor yang diberikan kelas.
- P(x) adalah probabilitas prediktor sebelumnya.
Bagaimana Algoritma Naive Bayes Bekerja?
Mari kita pahami cara kerja algoritma ini dengan contoh berikut. Di bawah ini kita memiliki kumpulan data pelatihan cuaca dan variabel target yang sesuai Play (menyarankan bermain). Sekarang, kita perlu mengklasifikasikan apakah pemain akan bermain atau tidak berdasarkan kondisi cuaca. Mari simak langkah-langkah di bawah ini untuk melakukannya.
Langkah 1: Ubah kumpulan data menjadi tabel frekuensi
Langkah 2: Buat tabel kemungkinan dengan mencari probabilitas seperti probabilitas overcast (mendung) = 0,29 dan probabilitas play (bermain) – 0,64
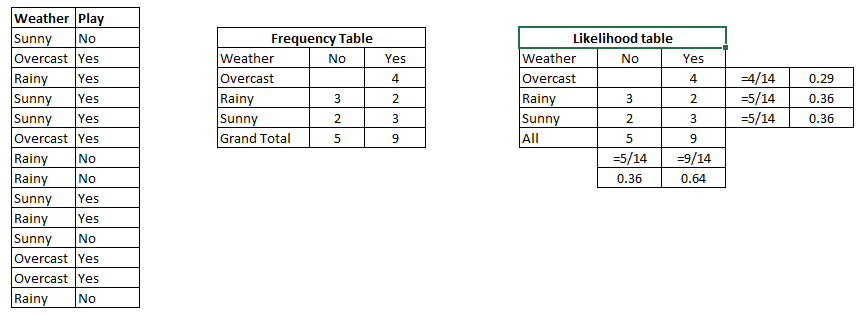
Langkah 3: Sekarang, gunakan persamaan naive bayesian untuk menghitung probabilitas posterior untuk setiap kelas. Kelas dengan probabilitas posterior tertinggi merupakan hasil prediksi.
Pertanyaan: Pemain akan bermain jika cuaca cerah. Apakah pernyataan ini benar?
Kita dapat menyelesaikannya dengan menggunakan metode probabilitas posterior yang dibahas diatas.
P(Yes | Sunny) = P( Sunny | Yes) * P(Yes) / P (Sunny)
Di sini kita memiliki P (Sunny | Yes) = 3/9 = 0,33, P(Sunny) = 5/14 = 0,36, P(Yes) = 9/14 = 0,64
Sekarang, P (Yes | Sunny) = 0,33 * 0,64 / 0,36 = 0,60, yang memiliki probabilitas lebih tinggi.
Naive Bayes menggunakan metode serupa untuk memprediksi probabilitas kelas yang berbeda berdasarkan berbagai atribut. Algoritma ini sebagian besar digunakan dalam klasifikasi teks dan dengan problem atau masalah yang memiliki banyak kelas.
Kelebihan dan Kekurangan Naive Bayes
Kelebihan:
- Mudah dan cepat untuk memprediksi kelas dengan kumpulan data uji. Algoritma ini juga bekerja dengan baik dalam prediksi multi kelas.
- Ketika asumsi kemandirian berlaku, pengklasifikasi naive bayes bekerja lebih baik dibandingkan dengan model lain seperti regresi logistik dan naive bayes juga membutuhkan lebih sedikit data pelatihan.
- Algoritma ini bekerja dengan baik dalam hal variabel input kategorikal dibandingkan variabel numerik.
Kekurangan:
- Jika variabel kategori memiliki kategori (dalam kumpulan data uji), yang tidak diamati dalam kumpulan data pelatihan, maka model akan menetapkan probabilitas 0 (nol) dan tidak dapat membuat prediksi. Ini sering dikenal sebagai “Frekuensi Nol”. Untuk mengatasinya, kita bisa menggunakan teknik smoothing. Salah satu teknik pemulusan yang paling sederhana disebut estimasi Laplace.
- Di sisi lain naive Bayes juga dikenal sebagai estimator yang buruk, sehingga keluaran probabilitas dari predict_proba tidak dianggap terlalu serius.
- Keterbatasan lain dari algoritma ini adalah asumsi prediktor independen. Dalam kehidupan nyata, hampir tidak mungkin kita mendapatkan satu set prediktor yang benar-benar independen.
Contoh Penggunaan Naive Bayes
Real Time Prediction: Naive Bayes adalah klasifikasi di machine learning yang sangat cepat. Dengan demikian, dapat digunakan untuk membuat prediksi secara real time.
Prediksi Multi Class: Algoritma ini juga terkenal dengan fitur prediksi multi class. Disini kita dapat memprediksi probabilitas kelas variabel target.
Text Classification / Spam Filtering / Sentiment Analysis: Klasifikasi naive bayes banyak digunakan dalam klasifikasi teks (karena hasil yang lebih baik dalam masalah multi class dan aturan independesi). Selain itu, algoritma ini memiliki tingkat keberhasilan yang lebih tinggi dibandingkan dengan algoritma lainnya. Akibatnya, algoritma ini banyak digunakan dalam pemfilteran spam (mengidentifikasi email spam) dan analisis sentimen untuk mengidentifikasi sentimen positif dan negatif.
Recommendation System: Naive Bayes Classifier dan Collaborative Filtering bersama-sama membangun sistem rekomendasi yang menggunakan pembelajaran mesin dan teknik penambangan data untuk menyaring informasi yang tidak terlihat dan memprediksi apakah penggunakan menginginkan sumber daya yang diberikan atau tidak.
Implementasi Naive Bayes dengan Python
Pertama, kita buat file notebook baru di google colab. Bisa melalui link berikut https://colab.research.google.com/#create=true
Selanjutnya kita import libraries yang akan kita gunakan dalam klasifikasi.
import pandas as pd import numpy as np
Selanjutnya, kita akan memuat dataset. Dataset yang akan digunakan yaitu Social Network Ads. Kalian bisa download dataset tersebut disini. Kemudian kita bagi menjadi independent variabel dan dependent variabel. X merupakan independent variabel dan y merupakan dependent variabel.
dataset = pd.read_csv('Social_Network_Ads.csv')
X = dataset.iloc[:, :-1].values
y = dataset.iloc[:, -1].values
Setelah itu, kita bagi dataset ke dalam training set dan test set dengan perbandingan 0.25 untuk test set dan 0.75 untuk training set. Data training set nantinya digunakan dalam pelatihan model naive bayes. Sedangkan, data test set digunakan dalam pengujian model yang telah dilatih.
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)
Kemudian, kita perlu melakukan tahapan feature scaling supaya nilai setiap feature yang terdapat dataset tidak terlalu jauh. Disini kita akan menggunakan StandardScaler untuk melakukan feature scaling.
from sklearn.preprocessing import StandardScaler sc = StandardScaler() X_train = sc.fit_transform(X_train) X_test = sc.transform(X_test)
Sekarang kita akan melatih model naive bayes dengan menggunakan data training set.
from sklearn.naive_bayes import GaussianNB classifier = GaussianNB() classifier.fit(X_train, y_train)
Terakhir, kita uji model yang telah kita buat dengan memprediksi data test set dan hasil akurasi dari model yang telah kita buat yaitu 0.9
from sklearn.metrics import confusion_matrix, accuracy_score y_pred = classifier.predict(X_test) accuracy_score(y_test, y_pred)
Selamat! sekarang kita sudah tahu tentang naive bayes beserta implementasinya di bahasa pemrograman python.