
Pada artikel kali ini, kita akan belajar perbedaan decision tree dan random forest pada pembelajaran mesin atau machine learning. Tetapi sebelum itu, kita harus memahami tentang cara kerja dari decision tree dan random forest.
Decision Tree adalah algoritma supervised learning yang dapat digunakan untuk klasifikasi dan regresi. Decision Tree atau Pohon Keputusan hanyalah serangkaian keputusan berurutan yang dibuat untuk mencapai hasil tertentu. Berikut adalah ilustrasi dari decision tree.
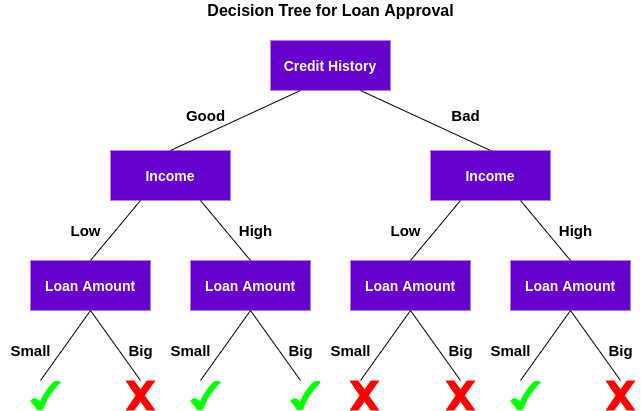
Mari kita pahami cara kerja decision tree.
Pertama, memeriksa apakah pelanggan memiliki sejarah kredit yang baik. Berdasarkan hal tersebut, maka mengklasifikasikan nasabah menjadi dua kelompok, yaitu nasabah dengan riwayat kredit baik dan nasabah dengan riwayat kredit buruk.
Kemudian, memeriksan pendapatan pelanggan dan sekali lagi mengklasifikasikannya menjadi dua kelompok. Terakhir, memeriksa jumlah pinjaman yang diminta oleh pelanggan. Berdasarkan hasil pengecekan ketiga fitur tersebut, decision tree memutuskan apakah pinjaman nasabah harus disetujui atau tidak.
Fitur atau atribut dan kondisi dapat berubah berdasarkan data dan kompleksitas masalah tetaoi gagasan keseluruhannya tetap sama. Jadi, decision tree membuat serangkaian keputusan berdasarkan serangkaian fitur atau atribut yang ada dalam data. Dalam hal ini adalah riwayat kredit, pendapat, dan jumlah pinjaman.
Sekarang, kalian pasti bertanya-tanya. Mengapa decision tree memeriksa skor kredit terlebih dahulu dan bukan pendapatannya ?
Ini dikenal sebagai kepentingan fitur dan urutan atribut yang akan diperiksa ditentukan berdasarkan kriterian seperti Gini Impurity Index atau Information Gain.
Algoritma decision tree cukup mudah dipahami dan diinterpretasikan. Namun seringkali, single tree tidak cukup untuk memberikan hasil yang efektif. Disinilah algoritma random forest muncul.
Random Forest adalah algorima pembelajaran mesin berbasis pohon yang memanfaatkan kekuatan beberapa pohon keputusan untuk membuat keputusan.
Tapi kenapa kita menyebutnya “random” forest ? Hal ini karena hutan pohon keputusan yang dibuat secara acak. Setiap node di pohon keputusan bekerja pada subset fitur acak untuk menghitung output. Random Forest kemudian menggabungkan keluaran dari masing-masing pohon keputusan untuk menghasilkan keluaran akhir.
Dengan kata lain, algoritma random forest menggabungkan keluaran dari beberapa pohon keputusan (yang dibuat secara acak) untuk menghasilkan keluaran akhir.

Proses menggabungkan output dari beberapa model individu (juga dikenal sebagai weak learners) disebut Ensemble Learning. Sekarang pertanyaannya adalah, bagaiman kita dapat memutuskan algoritma mana yang akan dipilih antara decision tree dan random forest ? Mari kita lihat keduanya dengan mengimplementasikan secara langsung dengan bahasa pemrograman Python.
Implementasi Decision Tree vs Random Forest dengan Python
Pada bagian ini, kita akan menggunakan Python untuk menyelesaikan masalah klasifikasi biner menggunakan decision tree dan random forest. Kemudian kita akan membandingkan hasil dari decision tree dan random forest. Setelah itu, melihat mana yang paling cocok dengan masalah kita.
Pertama, kita buat file notebook baru di google colab. Bisa melalui link berikut https://colab.research.google.com/#create=true
Selanjutnya kita import libraries yang akan kita gunakan dalam klasifikasi.
import pandas as pd import numpy as np import matplotlib.pyplot as plt from sklearn.metrics import f1_score from sklearn.model_selection import train_test_split
Selanjutnya, kita akan memuat dataset. Dataset yang akan digunakan yaitu Loan Prediction. Kalian bisa download dataset tersebut disini. Kemudian, kita tampilkan 5 baris data teratas.
df=pd.read_csv('dataset.csv')
df.head()
Dataset terdiri dari 614 baris dan 13 fitur, termasuk riwayat kredit, status perkawinan, jumlah pinjaman, dan jenis kelamin. Disini, variabel targetnya adalah Loan_Status yang menunjukkan apakah seseorang harus diberi pinjaman atau tidak.
Selanjutnya, kita ubah categorical variables ke dalam numerical variables.
df['Gender']=df['Gender'].map({'Male':1,'Female':0})
df['Married']=df['Married'].map({'Yes':1,'No':0})
df['Education']=df['Education'].map({'Graduate':1,'Not Graduate':0})
df['Dependents'].replace('3+',3,inplace=True)
df['Self_Employed']=df['Self_Employed'].map({'Yes':1,'No':0})
df['Property_Area']=df['Property_Area'].map({'Semiurban':1,'Urban':2,'Rural':3})
df['Loan_Status']=df['Loan_Status'].map({'Y':1,'N':0})
Setelah diubah, kita akan mengecek mising value pada dataset. Jika terdapat mising value maka nanti akan diisi dengan nilai rata-rata untuk masing-masing kolom.
rev_null=['Gender','Married','Dependents','Self_Employed','Credit_History','LoanAmount','Loan_Amount_Term']
df[rev_null]=df[rev_null].replace({np.nan:df['Gender'].mode(),
np.nan:df['Married'].mode(),
np.nan:df['Dependents'].mode(),
np.nan:df['Self_Employed'].mode(),
np.nan:df['Credit_History'].mode(),
np.nan:df['LoanAmount'].mean(),
np.nan:df['Loan_Amount_Term'].mean()})
Sekarang, kita pisahkan dataset menjadi 80% untuk data training dan 20% untuk data testing.
X=df.drop(columns=['Loan_ID','Loan_Status']).values Y=df['Loan_Status'].values X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size = 0.2, random_state = 42)
Karena kita memiliki training set dan testing set, saatnya untuk melatih model dan mengklasifikasikannya. Pertama, kita akan melatih model decision tree terlebih dahulu.
from sklearn.tree import DecisionTreeClassifier dt = DecisionTreeClassifier(criterion = 'entropy', random_state = 42) dt.fit(X_train, Y_train) dt_pred_train = dt.predict(X_train)
Selanjutnya, kita akan mengevaluasi model decision tree menggunakan F1-Score. F1-Score adalah rata-rata harmonik presisi dan daya ingat yang diberikan oleh rumus.
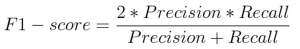
Mari evaluasi kinerja model kita menggunakan F1 Score.
dt_pred_train = dt.predict(X_train)
print('Training Set Evaluation F1-Score=>',f1_score(Y_train,dt_pred_train))
dt_pred_test = dt.predict(X_test)
print('Testing Set Evaluation F1-Score=>',f1_score(Y_test,dt_pred_test))
Disini kalian dapat melihat bahwa decision tree bekerja dengan baik pada evaluasi dalam sampel, tetapi kinerjanya menurun secara drastis pada evaluasi di luar sampel. Menurut kalian mengapa demikian? Sayangnya, model decision tree kita overfitting pada data pelatihan. Apakah random forest bisa menyelesaikan masalah ini?
Mari kita coba menggunakan model Random Forest.
# Building Random Forest Classifier
from sklearn.ensemble import RandomForestClassifier
rfc = RandomForestClassifier(criterion = 'entropy', random_state = 42)
rfc.fit(X_train, Y_train)
# Evaluating on Training set
rfc_pred_train = rfc.predict(X_train)
print('Training Set Evaluation F1-Score=>',f1_score(Y_train,rfc_pred_train))
# Evaluating on Test set
rfc_pred_test = rfc.predict(X_test)
print('Testing Set Evaluation F1-Score=>',f1_score(Y_test,rfc_pred_test))
Disini, kita dapat dengan jelas melihat bahwa model random forest tampil jauh lebih baik daripada decision tree dalam evaluasi di luar sampel. Mari kita bahas alasan di balik ini di bagian selanjutnya.
Mengapa Model Random Forest Kita Mengungguli Decision Tree?
Random Forest memanfaatkan kekuatan beberapa pohon keputusan atau multiple decision tree. Itu tidak bergantung pada kepentingan fitur yang diberikan oleh pohon keputusan tunggal.
Jadi random forest cocok untuk situasi ketika kita memiliki dataset yang besar dan interpretabilitas bukanlah perhatian utama.
Decision Tree jauh lebih mudah untuk ditafsirkan dan dipahami. Karena random forest menggabungkan beberapa pohon keputusan. Hal tersebut menjadi lebih sulit untuk ditafsirkan.
Selain itu, random forest memliki waktu pelatihan yang lebih tinggi daripada decision tree. Kita harus mempertimbangkan hal ini karena saat kita menambah jumlah pohon di random forest, waktu yang dibutuhkan untuk melatih masing-masing pohon juga bertambah. Hal ini sering kali menjadi sangat penting saat kita bekerja dengan tenggat waktu yang ketat dalam proyek pembelajaran mesin.
Meskipun ketidakstabilan dan ketergantungan pada serangkaian fitur tertentu, decision tree sangat membantu karena lebih mudah ditafsirkan dan lebih cepat untuk dilatih. Siapa pun dengan sedikit pengetahuan tentang ilmu data juga dapat menggunakan pohon keputusan untuk membuat keputusan cepat berdasarkan data.
Pada dasarnya itulah yang perlu kalian ketahui tentang perbedaan decision tree dan random forest. Ini bisa menjadi rumit ketika kalian baru mengenal pembelajaran mesin atau machine learning, tetapi artikel ini membantu untuk menjelaskan perbedaan decision tree dan random forest.