
Artikel ini berusaha menjelaskan analisis audio batuk, yang menggunakan audio batuk pasien untuk deteksi COVID-19. Namun, metode ini merupakan diagnosis awal untuk pemeriksaan cepat dan tidak hadir sebagai pengganti prosedur medis lainnya.
Analisis Audio Batuk, salah satu terobosan AI dalam perawatan kesehatan, seringkali terbukti bermanfaat dalam mendiagnosis penyakit pernapasan dan paru-paru. COVID-19 (Penyakit Coronavirus 2019) telah berdampak buruk pada umat manusia, membuat deteksi dini pada pasien sangat penting untuk pengobatannya.
Analisis suara batuk sangat penting dalam mendiagnosis virus, di antara banyak gejala lainnya. Menerapkan analisis suara batuk untuk penilaian awal COVID-19 pada pasien dapat membantu karena ini merupakan cara yang sepenuhnya tanpa kontak untuk mendeteksi virus.
Untuk membangun sistem yang dapat deteksi COVID-19 melalui suara batuk pasien, kita akan melakukan pra-proses beberapa data audio batuk dan melatih model yang mengklasifikasikan audio ke dalam kategori COVID-positif atau COVID-negatif. Sekarang, kita telah mengidentifikasi bahwa kita adalah masalah klasifikasi audio.
Note
Harap diperhatikan bahwa dasar-dasar pemrosesan audio tidak tercakup dalam cakupan artikel ini. Para pembaca diharapkan memiliki pemahaman dasar tentang data audio.
Dataset
Dataset yang digunakan untuk melatih model terdiri dari hampir 170 file audio yang terdiri dari audio pasien berlabel – not_covid/covid. Data asli dan versi pra-prosesnya tersedia di kaggle atau kalian bisa cek di sini. Jangan lupa untuk mendownload datasetnya. Meskipun versi audio pra-pemrosesan juga tersedia di kumpulan data, kita akan menangani file audio dan melakukan semuanya dari langkah 0.
Metodologi
Sekarang, kita tahu bahwa audio adalah bentuk data yang tidak terstruktur dan menanganinya secara langsung tidak mungkin untuk model Pembelajaran Mesin. Oleh karena itu, kita akan melakukan ekstraksi fitur pada file audio.
Selanjutnya, kita akan melatih Artificial Neural Network (ANN) pada fitur yang diekstraksi untuk mengklasifikasikannya ke dalam kategori covid dan bukan covid. Pendekatan bertahap untuk metode yang diadopsi digambarkan di bawah ini:
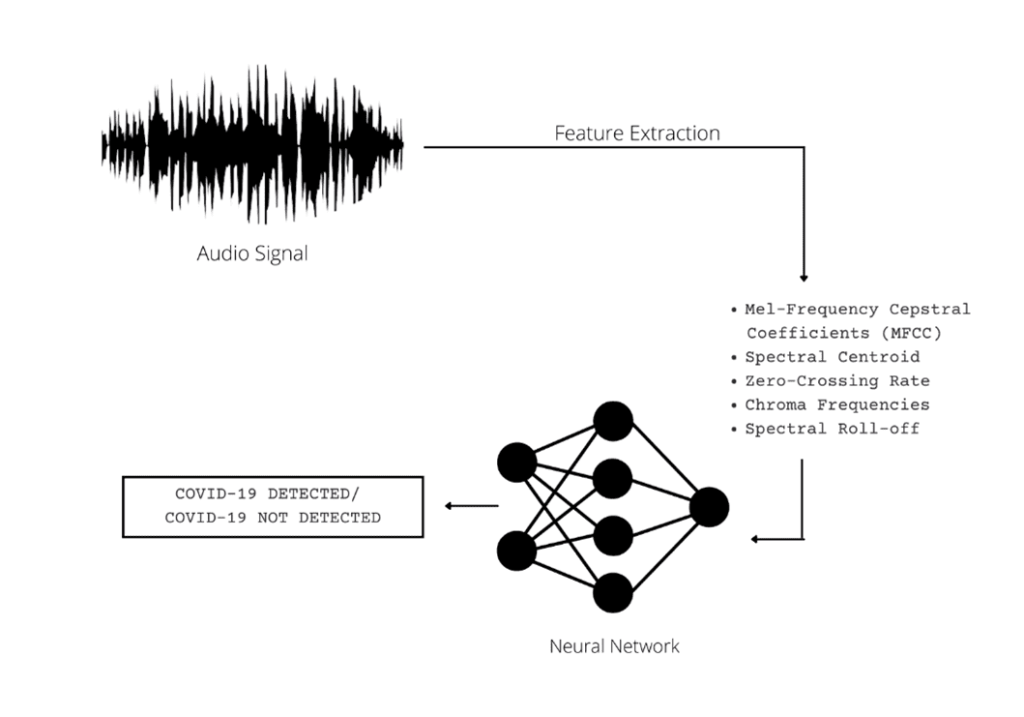
Sistem Deteksi COVID-19 dengan Analisis Audio Batuk
Fitur-fitur berikut akan diekstraksi dari file audio (penjelasan singkat masing-masing diberikan bersama):
1. Koefisien cepstral frekuensi mel (MFCC) (berjumlah 20):
Koefisien cepstral frekuensi mel (MFCCs) adalah koefisien yang secara kolektif membentuk MFC. Mereka berasal dari jenis representasi cepstral dari klip audio. Perbedaan antara cepstrum dan cepstrum frekuensi Mel adalah bahwa pada yang terakhir, pita frekuensi berjarak sama pada skala Mel, yang mendekati respons sistem pendengaran manusia lebih dekat daripada pita frekuensi dengan spasi linier yang digunakan dalam spektrum normal. Pembengkokan frekuensi ini memungkinkan representasi suara yang lebih baik, misalnya, dalam kompresi audio.
2. Centroid Spektral:
Ini mengukur amplitudo di pusat spektrum distribusi sinyal melalui jendela yang dihitung dari frekuensi Fourier-Transform dan informasi amplitudo.
3. Zero-Crossing Rate:
Zero-crossing rate (ZCR) adalah tingkat transisi sinyal dari positif ke nol ke negatif atau negatif ke nol ke positif. Nilainya telah banyak digunakan dalam pengenalan suara dan pencarian informasi musik untuk mengklasifikasikan suara perkusi.
4. Frekuensi Chroma:
Fitur Chroma adalah representasi audio yang kuat di mana seluruh spektrum diproyeksikan ke 12 nampan yang mewakili 12 seminada (atau kroma) yang berbeda.
5. Spectral Roll-off:
Spectral roll-off adalah frekuensi di bawah persentase tertentu dari total energi spektral.
Semua fitur ini merupakan ciri khas audio dan dapat digunakan untuk mengkategorikan audio secara khas. Dengan demikian, kita dapat menyimpulkan bahwa metodologi yang ingin kita adopsi mengubah masalah klasifikasi audio menjadi masalah klasifikasi data numerik.
Pra-Pemrosesan Data
Pada fase pra-pemrosesan, kami akan mengekstrak nilai fitur yang disebutkan di atas dari file audio. Ini dapat dicapai dengan menggunakan library pemrosesan audio Python yaitu Librosa. Kita dapat menginstall librosa dengan menggunakan pip sebagai berikut:
pip install librosa
Implementasi Python bertahap dari fase ekstraksi fitur diberikan di bawah ini:
1. Impor Perpustakaan yang Diperlukan
Pertama kita buka text editor, lalu pindahkan dataset yang kita download tadi ke folder project kita. Setelah itu, kita buat file dengan nama main.py. Berikut ini adalah perpustakaan yang perlu kita impor di file main.py
import pandas import numpy import os import pathlib import csv from sklearn.model_selection import train_test_split from sklearn.preprocessing import LabelEncoder, StandardScaler
2. Membuat semua Field Header untuk Dataset Final
Pada langkah ini, kita mendefinisikan file header dari dataset baru yang akan kita peroleh setelah ekstraksi fitur. Ini merupakan langkah opsional.
header = 'filename chroma_stft rmse spectral_centroid spectral_bandwidth rolloff zero_crossing_rate'
for i in range(1, 21):
header += f' mfcc{i}'
header += ' label'
header = header.split()
3. Ekstraksi Fitur
Ini adalah langkah paling penting dari fase pra-pemrosesan. Di sini, kita akan mengonversi file audio menjadi data numerik. Seperti yang dinyatakan sebelumnya, ini dilakukan dengan menggunakan Librosa. Di sini kita membaca setiap file audio, mengekstrak fitur-fiturnya menggunakan modul bawaan Librosa dan menyimpannya dalam file CSV baru.
import librosa
file = open('data_new_extended.csv', 'w')
with file:
writer = csv.writer(file)
writer.writerow(header)
for i in range(tot_rows):
source = train_csv['file_properties'][i]
file_name = '../input/coughclassifier-trial/trial_covid/'+source
y,sr = librosa.load(file_name, mono=True, duration=5)
chroma_stft = librosa.feature.chroma_stft(y=y, sr=sr)
rmse = librosa.feature.rms(y=y)
spec_cent = librosa.feature.spectral_centroid(y=y, sr=sr)
spec_bw = librosa.feature.spectral_bandwidth(y=y, sr=sr)
rolloff = librosa.feature.spectral_rolloff(y=y, sr=sr)
zcr = librosa.feature.zero_crossing_rate(y)
mfcc = librosa.feature.mfcc(y=y, sr=sr)
to_append = f'{source[:-3].replace(".", "")} {np.mean(chroma_stft)} {np.mean(rmse)} {np.mean(spec_cent)} {np.mean(spec_bw)} {np.mean(rolloff)} {np.mean(zcr)}'
for e in mfcc:
to_append += f' {np.mean(e)}'
file = open('data_new_extended.csv', 'a')
with file:
writer = csv.writer(file)
writer.writerow(to_append.split())
Sekarang, mari kita load dataset yang baru dibentuk.
data1 = pd.read_csv('../input/coughclassifier-trial/data_new_extended.csv')
data1
4. Pra-Pemrosesan Set Data Baru untuk Pelatihan Model
Setelah mendapatkan data dalam bentuk numerik, sangat penting untuk menjalani pra-pemrosesan agar dianggap cocok untuk pelatihan model. Langkah-langkah berikut mencakup pra-pemrosesan data numerik:
Menghapus kolom yang tidak perlu:
# Dropping unneccesary columns data1 = data1.drop(['filename'],axis=1)
Melakukan encoding pada label
labels = data1.iloc[:, -1] encoder = LabelEncoder() y = encoder.fit_transform(labels)
Melakukan Standard Scaling pada input features agar jarak nilai setiap features tidak terlalu jauh dan berada pada range [0,1]
scaler = StandardScaler() X = scaler.fit_transform(np.array(data1.iloc[:, :-1], dtype = float))
Memisah dataset ke dalam data training dan data testing.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
Baca Juga
Pembuatan Model
Untuk mengklasifikasikan data audio yang telah diproses sebelumnya, ada banyak model dan opsi yang tersedia; Namun, menentukan model terbaik adalah kuncinya. Karena kami memiliki data numerik (diperoleh setelah pra-pemrosesan sinyal audio), kami akan menggunakan ANN (Artificial Neural Network) yang akan dilatih pada 80% data – 20% sisanya akan digunakan untuk pengujian.
Diagram berikut menggambarkan dengan sangat rinci arsitektur model yang digunakan untuk menyelesaikan klasifikasi:
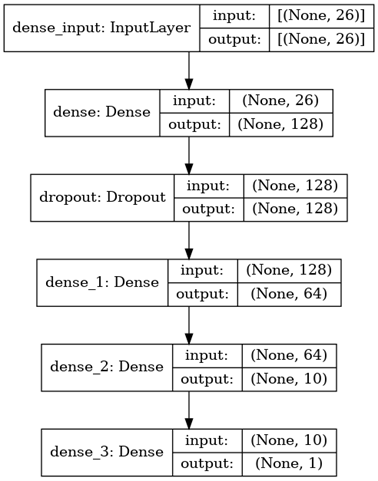
Berikut tahapan untuk membangun model dan pelatihan adalah sebagai berikut:
1. Impor Perpustakaan
import tensorflow as tf from tensorflow import keras from keras import models from keras import layers from keras.layers import Dropout
2. Membuat Model
Pertama, kita mendefinisikan model berurutan dan kemudian menambahkan lapisan ke dalamnya – sesuai arsitektur yang ditentukan di atas. Harap dicatat bahwa arsitektur telah dirancang menggunakan penyetelan hyperparameter.
model = tf.keras.Sequential() model.add(layers.Dense(128, activation='relu', input_shape=(X_train.shape[1],))) model.add(Dropout(0.3, input_shape=(60,))) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(10, activation='relu')) model.add(layers.Dense(1, activation='sigmoid')) model.summary()
Karena kita berurusan dengan data numerik yang disederhanakan, semua lapisan beroperasi dalam satu dimensi. Lapisan pertama adalah lapisan masukan. Berikut ini adalah lapisan padat pertama dengan 128 neuron.
Untuk mengatasi overfitting data pelatihan, mode ini menggunakan regularisasi dropout. Untuk ini, lapisan ketiga adalah lapisan dropout. Untuk memastikan bahwa data diuraikan dengan lebih baik, ada tiga lapisan yang lebih padat yang masing-masing terdiri dari 128, 64, dan 10 neuron.
Pilihan fungsi aktivasi: Pada lapisan keluaran, tugas klasifikasi biner diselesaikan dengan menggunakan fungsi aktivasi sigmoid. Ini adalah pilihan paling umum dalam kasus klasifikasi biner. Fungsi Aktivasi ReLU digunakan untuk semua layer padat dan dropout.
3. Penyusunan dan Pelatihan Model
Kita akan mengkompilasi model sebagai berikut:
- Optimizer: Adam
- Loss Function: binary_crossentropy
- Metric: Accuracy
Selanjutnya, kita akan melatih model tersebut selama 15 epoch.
model.compile(optimizer='adam',loss='binary_crossentropy',metrics=['accuracy']) model.fit(X_train, y_train, epochs=15)
Untuk akurasi pelatihan yang didapat adalah 98%.
4. Testing Model
Sekarang, kita akan menguji model dengan menggunakan dataset testing.
test_loss, test_acc = model.evaluate(X_test,y_test)
Untuk akurasi pengujian yang didapat adalah 94%.
Penutup
Berdasarkan performa teknologi kami pada set data pelatihan/validasi dan prospektif, kami menyimpulkan bahwa memang mungkin untuk mendiagnosis suara batuk COVID-19 secara akurat dan objektif saja menggunakan analisis suara batuk.
Dimungkinkan untuk menambah fitur berbasis batuk dengan gejala sederhana yang dapat diamati oleh orang tua yang menargetkan peningkatan kinerja lebih lanjut. Meskipun tingkat akurasinya cukup tinggi dan dapat diterima – harus dicatat bahwa penelitian ini mengusulkan model hanya untuk deteksi COVID-19 awal dan hasilnya harus dianggap sebagai indikasi.